
Part 1: Word Clouds, Swifties, and the Case for NLP
If you’ve been playing with LLMs lately, you might be wondering: why would anyone still use traditional NLP? You’ve got GPT-4 at your fingertips — why bother with term frequency, stopword filters, or spaCy pipelines? Just throw your raw text into the prompt and let the magic happen, right?
Well… not so fast.
Take Taylor Swift’s new album, The Tortured Poets Department. I ran the lyrics through two different pipelines to generate a word cloud. One used traditional NLP techniques — just some basic filtering, tokenization, and term frequency to surface the meaningful stuff. The other? I gave the same content to GPT-4-turbo and asked it to give me a “meaningful word cloud.”
The results? Wildly different.
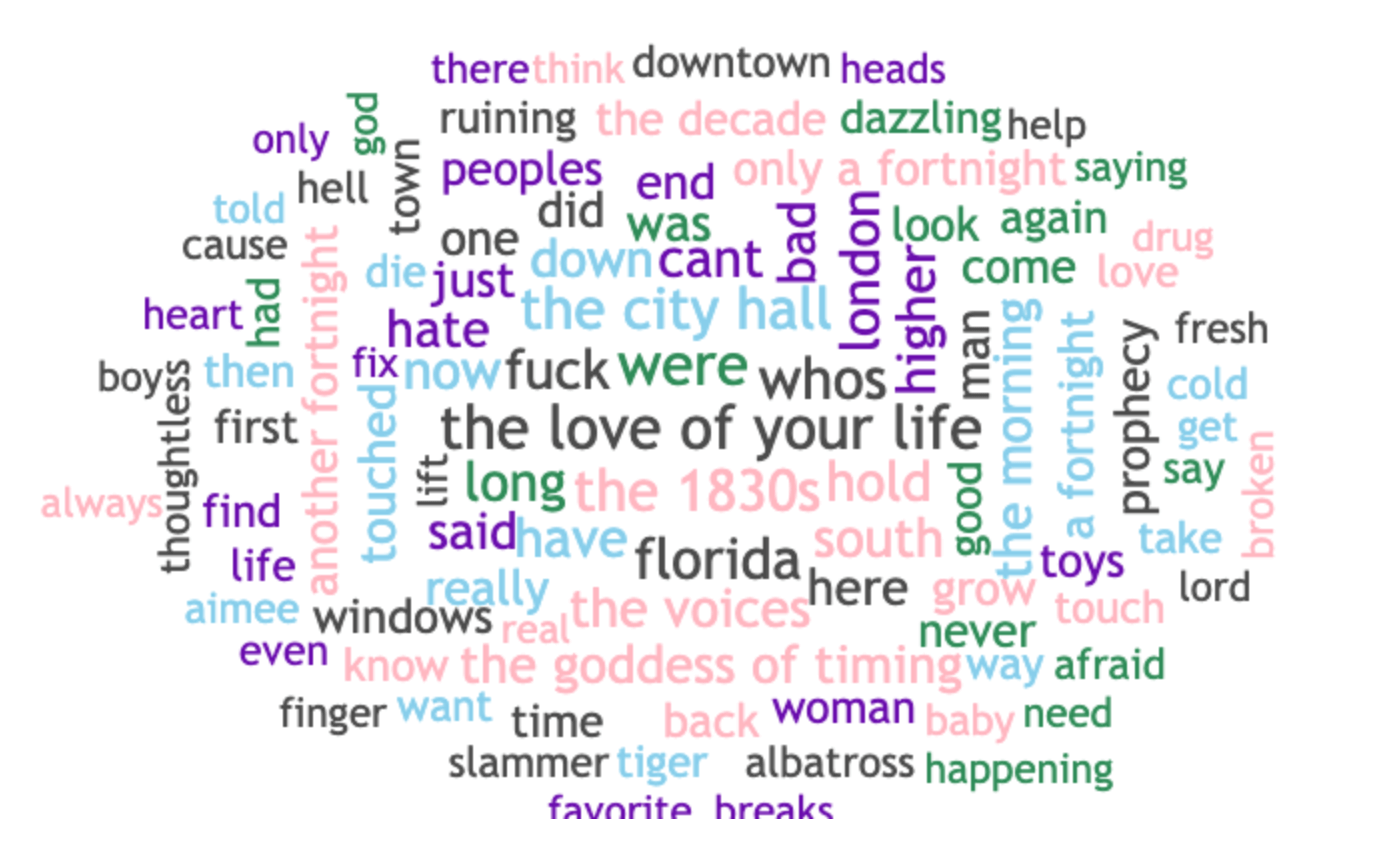
The NLP version surfaced phrases like “the 1830s,” “the love of your life,” “the goddess of timing,” and “florida!!!” — the kinds of niche but emotionally resonant phrases any Swiftie would recognize as thematically loaded. The LLM version? Mostly generic: “say,” “come,” “time,” “want,” and a few token nods to location or vibe. It was fine, but it didn’t get it. Not in the way that mattered.
Traditional NLP Word Cloud
ChatGPT Word Cloud V1 (Minimal Prompt)
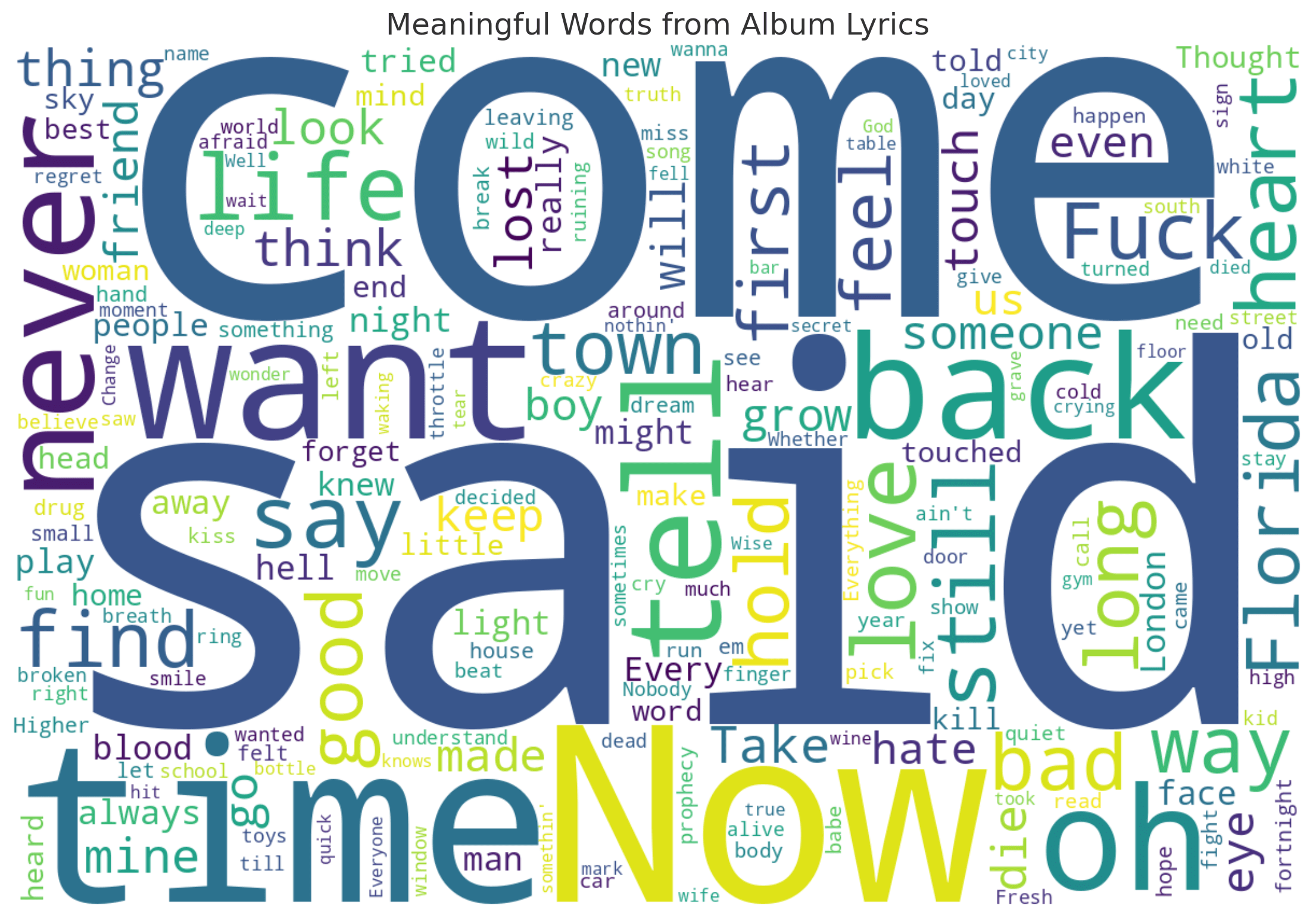
ChatGPT Word Cloud V2 (GPT Style , Top 100)

Let’s Talk Cost
Running that LLM query — just to get a word cloud — cost nearly $0.45 in API usage. Why? Because Taylor Swift writes lyrics. Lots of them. The album came in around 10,663 words, which converts to roughly 42,000 tokens — and when you’re feeding that to an LLM like GPT-4-turbo, you’re paying by the token.
Now scale that up: imagine trying to generate rich, live insights across a discography. Or worse, using this approach for thousands of users in a production system.
Here’s the thing no one tells you:
Not all consumption is good consumption.
Just because an LLM can consume 10K+ tokens doesn’t mean it should. You’re paying for every word — including the useless ones — unless you filter, chunk, and prioritize. And for that? Traditional NLP still does the job faster, cheaper, and smarter.
Part 1 (continued): The Taylor Swift Example — When Word Clouds Meet Reality
Let’s go back to our Tortured Poets Department experiment.
We ran 10,663 words of lyrics through GPT-4-turbo to extract a word cloud — and paid roughly $0.45 for the privilege.
The cost wasn’t the only issue. The result, while clean and readable, lacked nuance. It missed lyrical motifs, multi word expressions, and fan recognized phrasing. A traditional NLP version, on the other hand, picked up things like “only a fortnight,” “the city hall,” “the love of your life,” and “the 1830s” all deeply relevant in Swift’s lyrical world.
So, let’s say we want to use the LLM version anyway. How do we reduce the cost?
Option 1: Run Once, Cache Forever
The obvious solution is to preprocess once, store the results, and never send the full album to the LLM again. You could:
- Run the LLM once per album or song
- Store the output (summary, word cloud phrases, metadata)
- Serve cached results from a database or key-value store
That works — and it cuts down per-query cost to nearly zero after the first run. But even that first run still costs ~45 cents. Do it across a dozen albums? Now you’re at $5.40. Across 100 artists? $45+.
It adds up quickly especially if the results aren’t that deep or reusable.
Option 2: Fine-Tune an LLM That Gets Taylor Swift
What if the model itself understood Swift’s style, metaphors, references, and themes?
That’s where fine tuning comes in.
Let’s say we compile:
- Her entire discography (about 20× the size of TTPD)
- Critical reviews, scholarly essays, Reddit threads, fan theories
- Annotated lyrical breakdowns
That adds up to ~850,000 tokens, or about 213,000 words.
Using OpenAI’s GPT-3.5-turbo fine tuning pricing (as of March 2025):
| Cost Component | Rate | Est. Cost |
|---|---|---|
| Input Tokens | $0.008 / 1K | ~$6.80 |
| Output Tokens | $0.012 / 1K | ~$10.20 |
| Total | — | ~$17.00–$25.00 after iterations and prep |
Once trained, your model can produce richer, tailored interpretations — and at ~$0.03 per call, it’s way cheaper than raw GPT-4.
But here’s the twist:
Given the prolific nature of Taylor Swift and the ever expanding scope of her artistic output — new albums, vault tracks, live versions, evolving themes — you’re not just fine tuning once.
You’re maintaining a living model. That means periodic retraining, adding new context, refining outputs as the narrative evolves.
🎵 Now Do That for Every Musician…
Now imagine doing that for every artist with a complex catalog — Beyoncé, Bob Dylan, Mitski, Kendrick Lamar, Sufjan Stevens. Each has their own mythology, language, and world building.
That’s when it hits: this isn’t scalable with just fine tuning.
You either need:
- A highly customizable agent with modular understanding, or
- A hybrid system — where traditional NLP preprocessors carry the load, and LLMs are brought in only when it counts
And that leads us to Part 2…
Part 2: The Invisible Workhorse — Why NLP Still Powers RAG
By now it’s clear: letting a large language model chew through thousands of tokens of unstructured content is both expensive and often underwhelming. Whether you cache once or fine tune for nuance, there’s a limit to how far brute force LLM consumption can scale — especially if you’re trying to build generalized systems across domains, artists, or industries.
This is where traditional NLP makes its quiet comeback.
Look closely at any robust RAG (Retrieval-Augmented Generation) pipeline or multi agent orchestration framework and you’ll find them: preprocessors. They’ve just moved behind the curtain — but they’re still doing the heavy lifting.
🧠 Preprocessors: The Real Brains Behind “Context Injection”
In a typical RAG workflow, the user query isn’t sent directly to the LLM. Instead, it’s:
- Parsed using NLP tools to extract key entities, concepts, and intent
- Transformed into a vector or search friendly form
- Matched against a corpus that’s already been indexed, chunked, and cleaned
- Filtered, ranked, and condensed into a tight, relevant context window
And guess what powers steps 1–4?
→ Not GPT. Not Claude. Not Gemini.
It’s tokenizers, POS taggers, lemmatizers, chunkers, TF-IDF scorers, phrase extractors, and custom built heuristics.
It’s good old fashioned NLP — just tuned for a new generation of use cases.
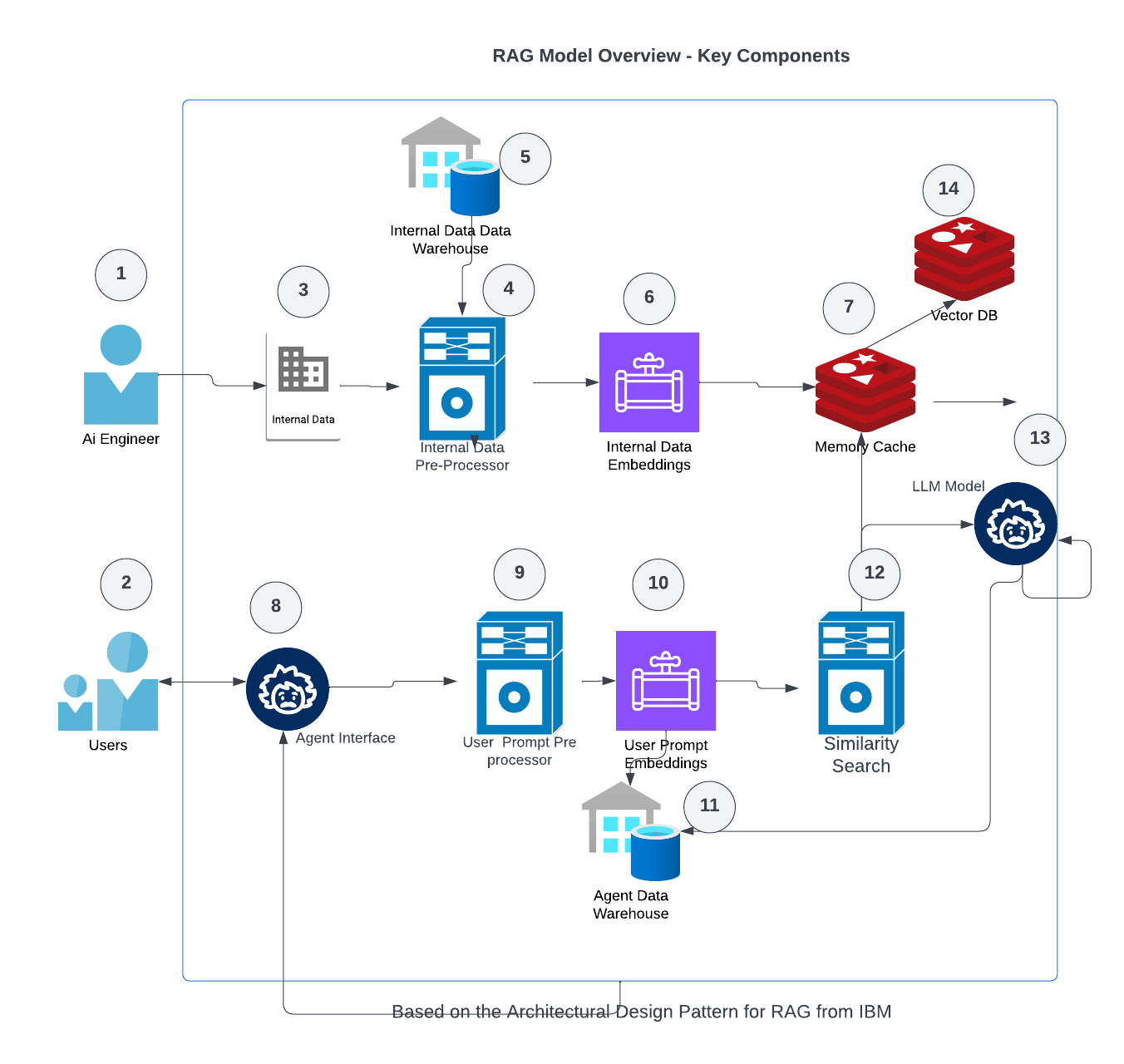
This architecture highlights how modern RAG systems still rely on traditional NLP. Preprocessors (4 and 9) do the heavy lifting before any LLM ever sees the data.
If you look at the IBM RAG reference architecture, it doesn’t assume the LLM will magically figure everything out. Instead, it assumes you’ll:
- Clean and prepare your documents first
- Split them into digestible units
- Enrich them with metadata
- Rank them by relevance before ever hitting the model
Without those steps, you’re just shoveling noise into an expensive black box. That’s how you end up with hallucinations, bad matches, and token bloat — the LLM equivalent of garbage in, garbage out and a nice bill for the privelege.
Sidebar: What About Business Data?
Everything so far has focused on creative, nuanced content like music lyrics. But what if the data you’re working with is more traditional like customer service transcripts, call logs, or chat support threads?
Here, the dynamics change and LLMs often perform better out of the box.
Repetitive, Structured Language
In customer service, language is often predictable and pattern based:
- “I can’t log in”
- “Please reset my password”
- “Where’s my order?”
LLMs excel in these contexts because:
- The language is simple and consistent
- Common intent categories can be learned easily
- Fine-tuning is often unnecessary
But Preprocessors Still Matter
Even in structured domains, you still need to clean and prep the data:
- Split transcripts by speaker turns
- Remove filler language and disfluencies
- Redact sensitive PII (names, addresses, card numbers)
- Tag metadata like sentiment, channel, product category
With this prep, LLMs can:
- Summarize the call in plain language
- Flag escalations or emotional tone
- Recommend follow ups or classify outcomes
With creative content, LLMs need help understanding nuance.
With business content, LLMs need help navigating structure.
Preprocessors are still key — just in a different role.
So What’s the Takeaway?
The smartest AI systems today don’t try to replace traditional NLP — they build on it. Preprocessors are how you scale with precision. They keep your context windows tight, your embeddings meaningful, and your LLM responses grounded in reality.
So is traditional NLP dead?
Not even close. It’s just hiding in plain sight — doing the real work so your LLM doesn’t have to.